Is Value Learning Really the Main Bottleneck in Offline RL?
NeurIPS 2024
-
Seohong Park
UC Berkeley -
Kevin Frans
UC Berkeley -
Sergey Levine
UC Berkeley -
Aviral Kumar
Carnegie Mellon University
Motivation
- The main difference between offline reinforcement learning (RL) and imitation learning is the use of a value function, and most prior works in offline RL focus on learning better value functions with better techniques.
- So value function learning is the main bottleneck in offline RL... right?
- In this work, we show that this is often not the case in practice!
Analyzing the bottlenecks of offline RL
- Our main goal in this work is to understand how the performance of offline RL can be bottlenecked in practice.
- There are three potential bottlenecks in offline RL:
- (B1) Imperfect value estimation from data
- (B2) Imperfect policy extraction from the learned value function
- (B3) Imperfect policy generalization to test-time states that the policy visits during evaluation
- Note that the bottleneck of an offline RL algorithm can always be attributed to one or some of these factors, given that the agent will attain optimal performance if all of them are perfect.
- So all we need is to dissect these components individually!
Main hypothesis
-
Let's first state our main research hypothesis in this work:
"The main bottleneck in offline RL is policy learning, not value learning."
- In other words, (though of course value learning is important,) we argue that how the policy is extracted from the value function (B2) and how well the policy generalizes to states that it visits at evaluation time (B3) are often the main factors that significantly affect both performance and scalability in many problems.
- To verify this hypothesis, we conduct two main analyses in this work: in the first analysis, we compare value learning and policy extraction (B1 and B2), and in the second analysis, we analyze the effect of policy generalization (B3).
TL;DR
-
Here's a tl;dr of our analyses for those who want it 🙂:
(1) Policy extraction is often more important than value learning: Do not use weighted behavior cloning (AWR); always use behavior-constrained policy gradient (DDPG+BC).
(2) Test-time policy generalization is one of the most significant bottlenecks in offline RL: Current offline RL is often already great at learning an effective policy on dataset states, and the performance is often simply determined by its performance on out-of-distribution states.
Analysis 1: Is it the value or the policy? (B1 and B2)
- What's more important: value learning or policy extraction?
- To answer this question, we run different algorithms with different amounts of data for value function training and policy extraction, and draw data-scaling matrices to visualize the results.
- This will tell us (1) whether the performance is bottlenecked by the value or the policy and (2) the performance difference between various value learning and policy extraction algorithms.
- To clearly dissect value learning and policy extraction, we focus on offline RL methods with decoupled value and policy learning phases in this work (e.g., IQL, one-step RL, CRL, etc.). This might sound a bit restrictive, but we will show that policy learning is often the main bottleneck even in these decoupled methods!
Analysis setup
- We consider the following algorithms and environments in this analysis.
- Three value learning algorithms: (1) Implicit Q-learning (IQL), (2) One-step RL (SARSA), (3) Contrastive RL (CRL).
-
Three policy extraction algorithms:
- (1) Weighted behavioral cloning (e.g., AWR, RWR, AWAC, etc.): $$\begin{aligned} \max_\pi \ \mathcal{J}_\mathrm{AWR}(\pi) = \mathbb{E}_{s, a \sim \mathcal{D}}[e^{\alpha (Q(s, a) - V(s))} \log \pi(a \mid s)], \end{aligned}$$ $$ \newcommand{\rphantom}[1]{\mathrel{\phantom{#1}}} \begin{aligned} &\rphantom{=} \max_\pi \ \mathcal{J}_\mathrm{AWR}(\pi) \\ &= \mathbb{E}_{s, a \sim \mathcal{D}}[e^{\alpha (Q(s, a) - V(s))} \log \pi(a \mid s)], \end{aligned} $$ where \(\alpha\) is an (inverse) temperature parameter.
- (2) Behavior-constrained policy gradient (e.g., DDPG+BC, TD3+BC, etc.): $$\begin{aligned} \max_\pi \ \mathcal{J}_\mathrm{DDPG+BC}(\pi) = \mathbb{E}_{s, a \sim \mathcal{D}}[Q(s, \mu^\pi(s)) + \alpha \log \pi(a \mid s)], \end{aligned}$$ $$\begin{aligned} &\rphantom{=} \max_\pi \ \mathcal{J}_\mathrm{DDPG+BC}(\pi) \\ &= \mathbb{E}_{s, a \sim \mathcal{D}}[Q(s, \mu^\pi(s)) + \alpha \log \pi(a \mid s)], \end{aligned}$$ where \(\mu^\pi(s)\) is the mean of the policy, and \(\alpha\) is a hyperparameter that controls the strength of the BC regularizer.
- (3) Sampling-based action selection (e.g., SfBC, BCQ, IDQL, etc.): $$ \DeclareMathOperator*{\argmax}{arg\,max} \DeclareMathOperator*{\argmin}{arg\,min} \begin{aligned} \pi(s) = \argmax_{a \in \{a_1, \ldots, a_N\}}[Q(s, a)], \end{aligned} $$ where \(a_1, \ldots, a_N\) are sampled from the learned BC policy \(\pi^\beta(\cdot \mid s)\).
- Eight tasks (including goal-conditioned ("gc-") and pixel-based ones!): (1) gc-antmaze-large, (2) antmaze-large, (3) d4rl-hopper, (4) d4rl-walker2d, (5) exorl-walker, (6) exorl-cheetah, (7) kitchen, (8) (pixel-based) gc-roboverse.
Results

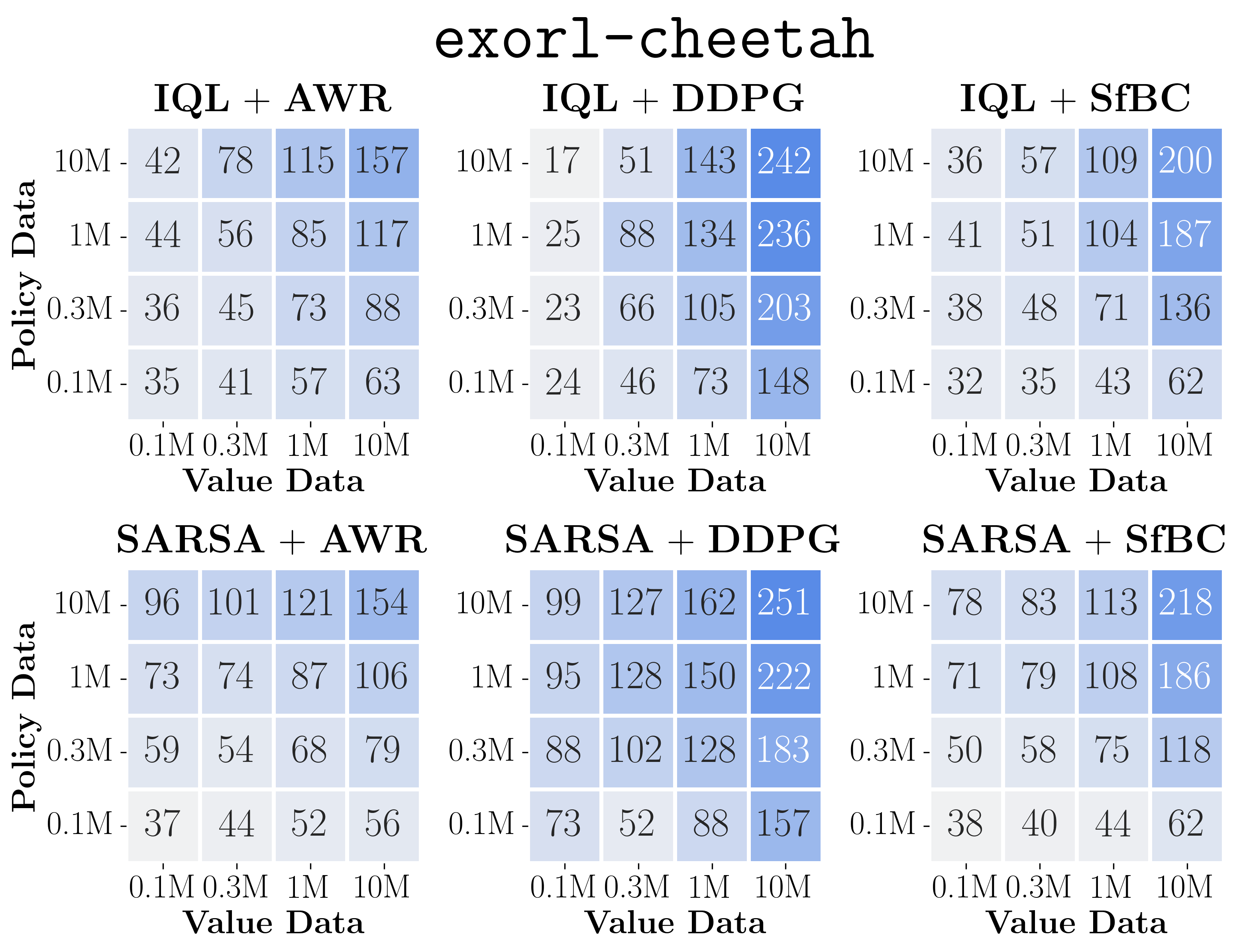
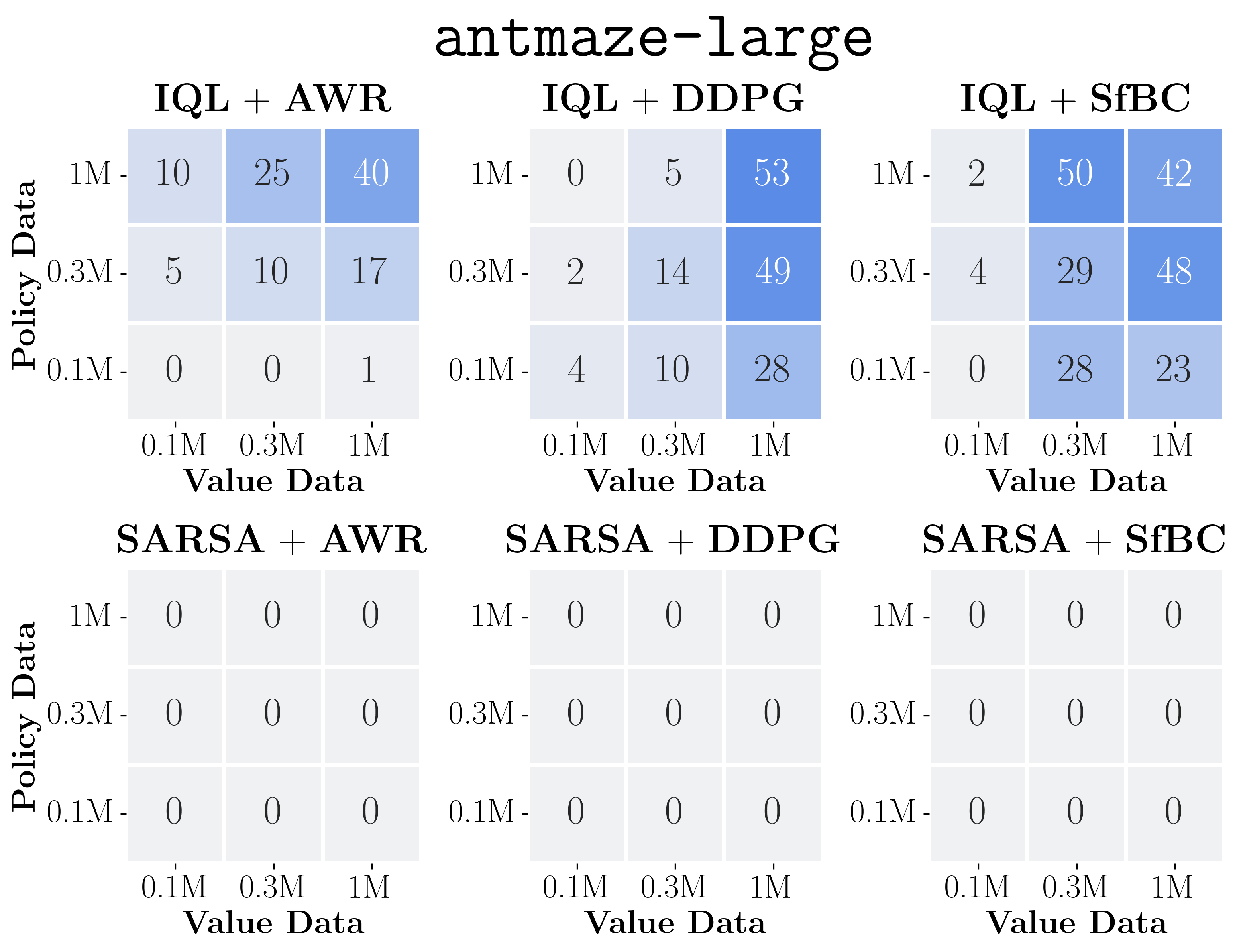

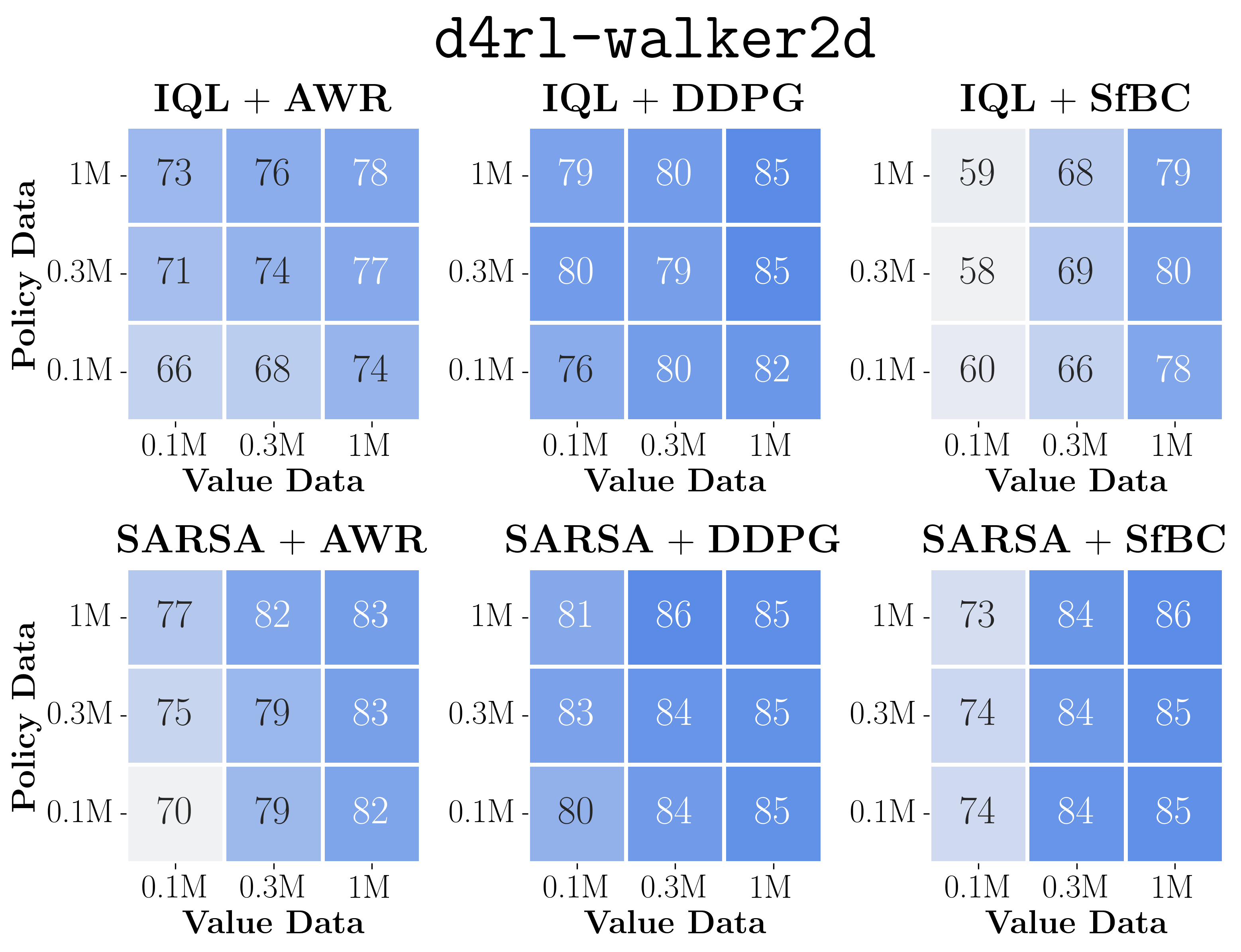
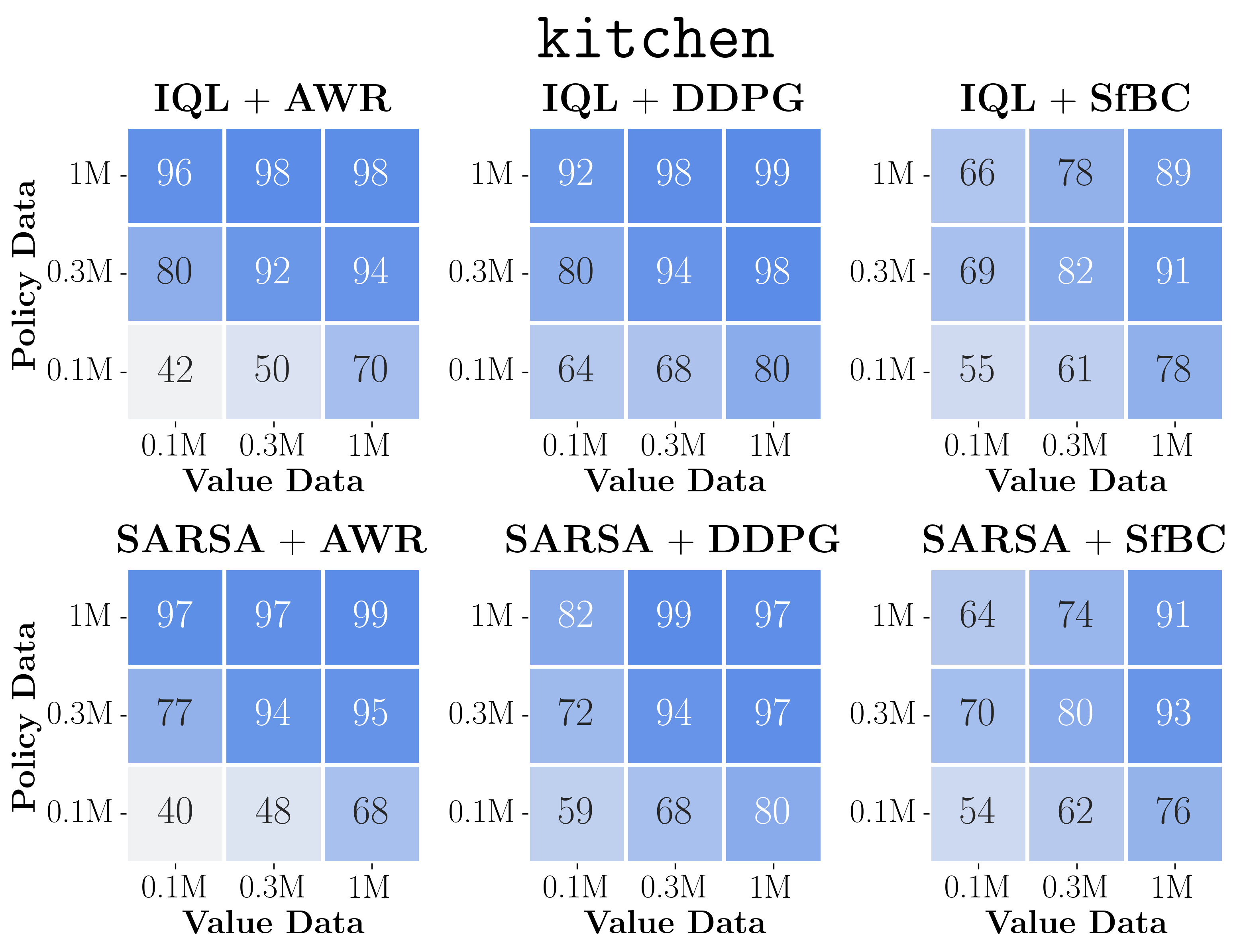
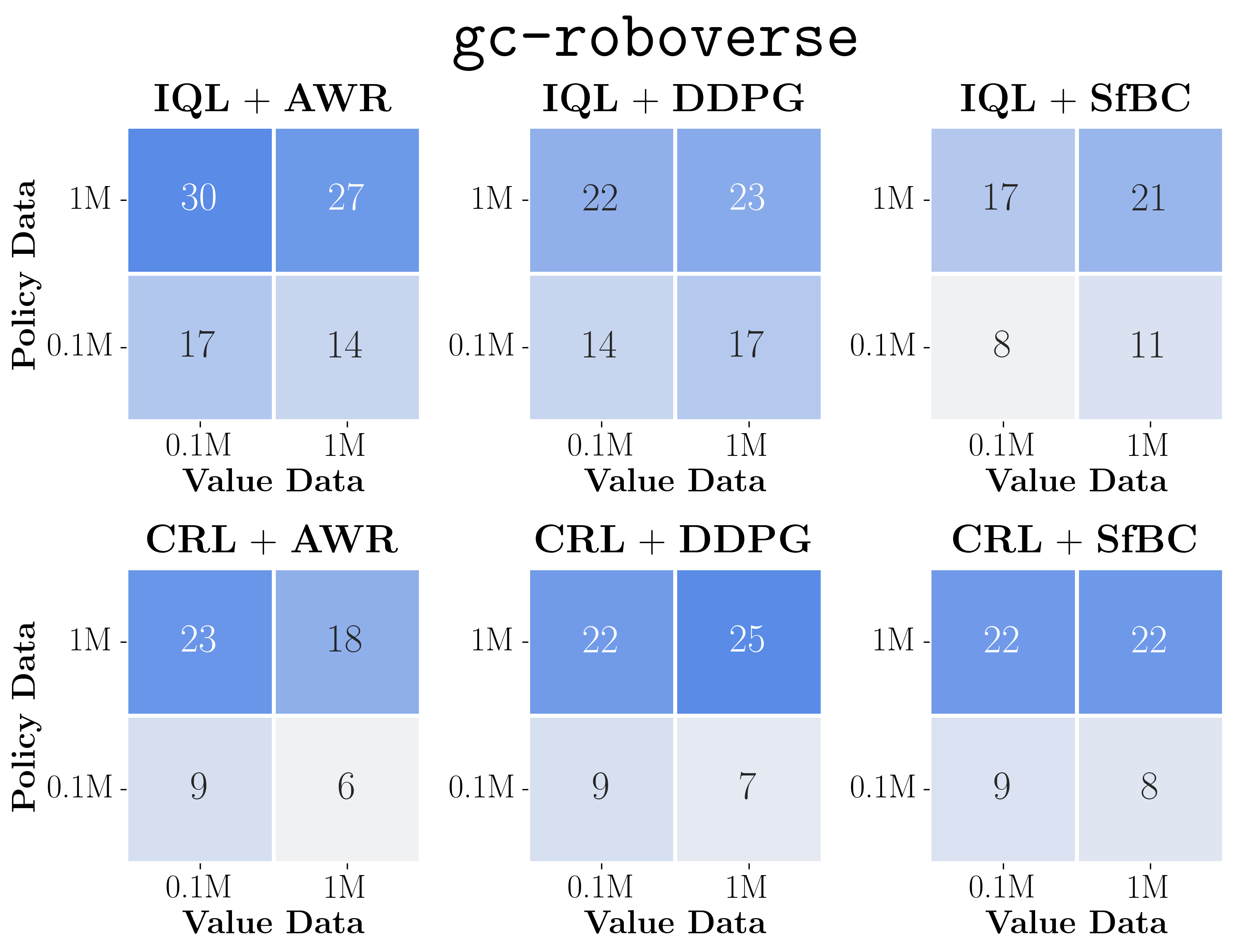
- The plots above show the data-scaling matrices. We highlight the results on exorl-walker and exorl-cheetah. Click the above button to see the full data-scaling matrices on eight tasks, aggregated from a total of 7744 runs. We individually tuned policy extraction hyperparameters for each matrix entry.
- By looking at color gradients, we can see how the performance of each algorithm scales with more data and/or how it is bottlenecked. Below, we highlight some key observations.
- First, we can see that policy extraction algorithms often affect the performance and data-scaling trends much more than value learning objectives in general (perhaps except antmaze-large), even though they extract policies from the same value function!
- Among policy extraction algorithms, we find that DDPG+BC almost always achieves the best performance and scaling behaviors across the board, followed by SfBC, and the performance of AWR falls significantly behind the other two in many cases.
- We can also see that the data-scaling matrices of AWR always have vertical or diagonal color gradients, which indicates that it does not fully utilize the value function (see below for clearer evidence).
- Read the paper for further discussions!
Deep dive: Why is DDPG+BC often much better than AWR?
- Although AWR and DDPG+BC are theoretically equivalent in some sense, we saw that DDPG+BC often leads to significantly better performances. Why is this the case?
- The main difference between AWR and DDPG+BC is in their objective: $$\begin{aligned} \mathcal{J}_\mathrm{AWR}(\pi) &= \mathbb{E}_{s, a \sim \mathcal{D}}[\underbrace{e^{\alpha (Q(s, a) - V(s))} \log \pi(a \mid s)}_{\text{Mode-covering}}], \\ \mathcal{J}_\mathrm{DDPG+BC}(\pi) &= \mathbb{E}_{s, a \sim \mathcal{D}}[\underbrace{Q(s, \mu^\pi(s))}_{\text{Mode-seeking}} + \underbrace{\alpha \log \pi(a \mid s)}_{\text{Mode-covering}}]. \end{aligned}$$ $$\begin{aligned} &\rphantom{=} \mathcal{J}_\mathrm{AWR}(\pi) \\ &= \mathbb{E}_{s, a \sim \mathcal{D}}[\underbrace{e^{\alpha (Q(s, a) - V(s))} \log \pi(a \mid s)}_{\text{Mode-covering}}], \\ &\rphantom{=} \mathcal{J}_\mathrm{DDPG+BC}(\pi) \\ &= \mathbb{E}_{s, a \sim \mathcal{D}}[\underbrace{Q(s, \mu^\pi(s))}_{\text{Mode-seeking}} + \underbrace{\alpha \log \pi(a \mid s)}_{\text{Mode-covering}}]. \end{aligned}$$
- The key difference is that, AWR only has a mode-covering weighted behavioral cloning term, but DDPG+BC has both mode-seeking first-order value maximization and mode-covering behavioral cloning terms. In other words, DDPG+BC has two modes, but AWR has only one!
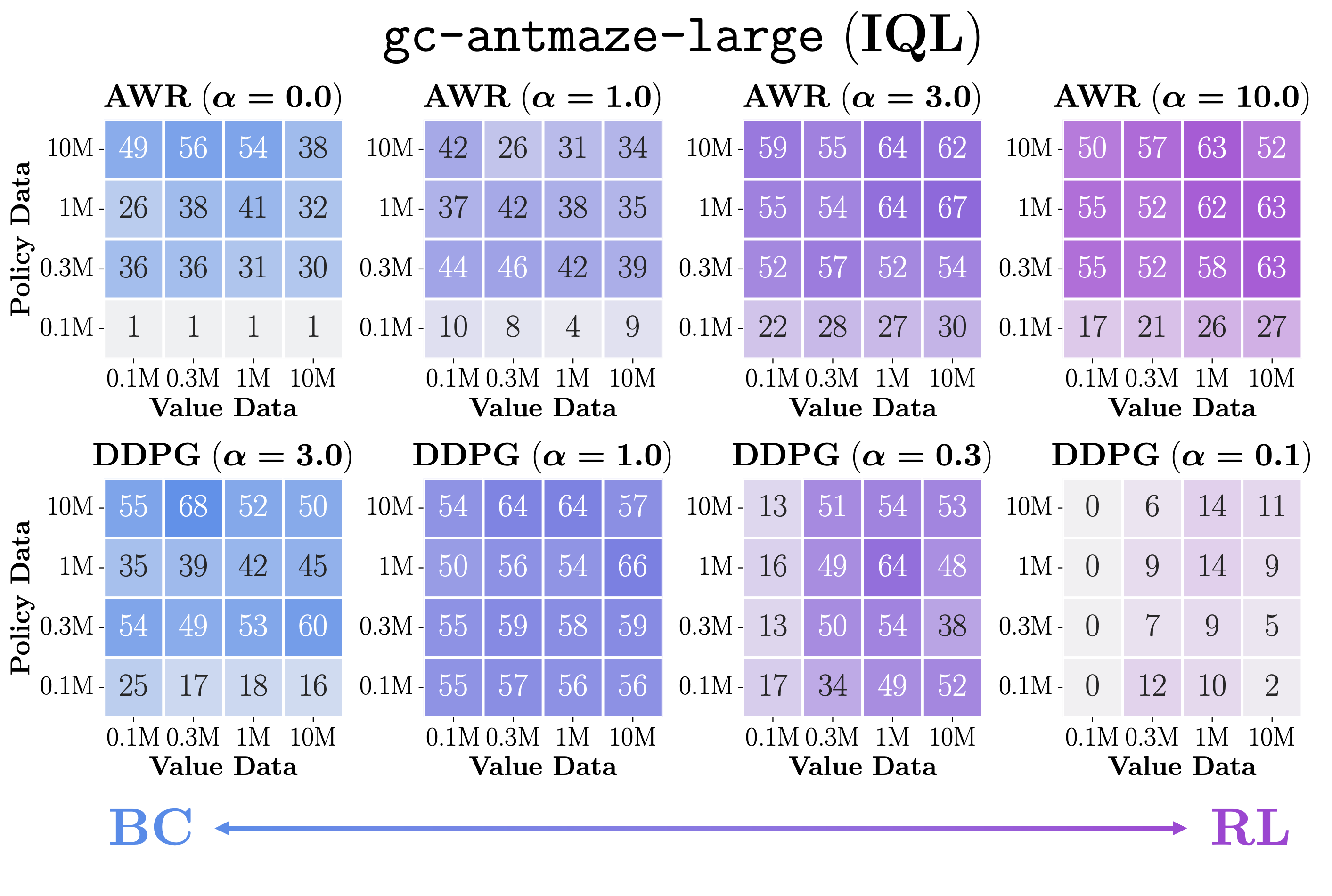
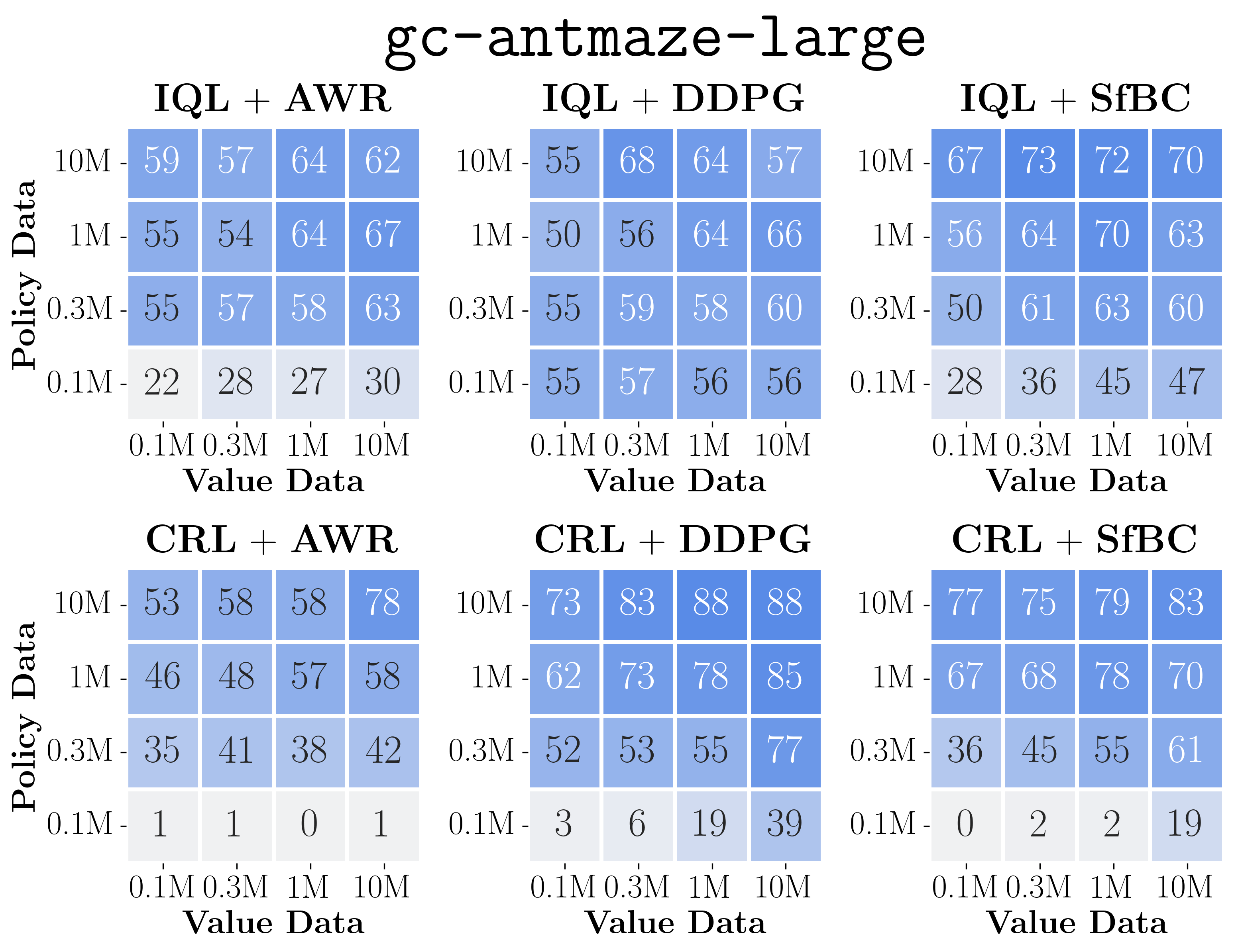
- To illustrate this, we draw data-scaling matrices of AWR and DDPG+BC with different temperature values (\(\alpha\)) on gc-antmaze-large. Note that \(\alpha = 0\) corresponds to BC in AWR and \(\alpha = \infty\) corresponds to BC in DDPG+BC.
- The results clearly show a difference between AWR and DDPG+BC. That is, AWR is always policy-bounded regardless of the BC strength \(\alpha\) (i.e., color gradients are always vertical), whereas DDPG+BC has two modes: it is policy-bounded when \(\alpha\) is large, and value-bounded and when \(\alpha\) is small.
- Very interestingly, an in-between value of \(\alpha = 1.0\) in DDPG+BC leads to the best of both worlds, significantly improving performance across the entire matrix (especially look at the bottom left corner with 0.1M datasets)!
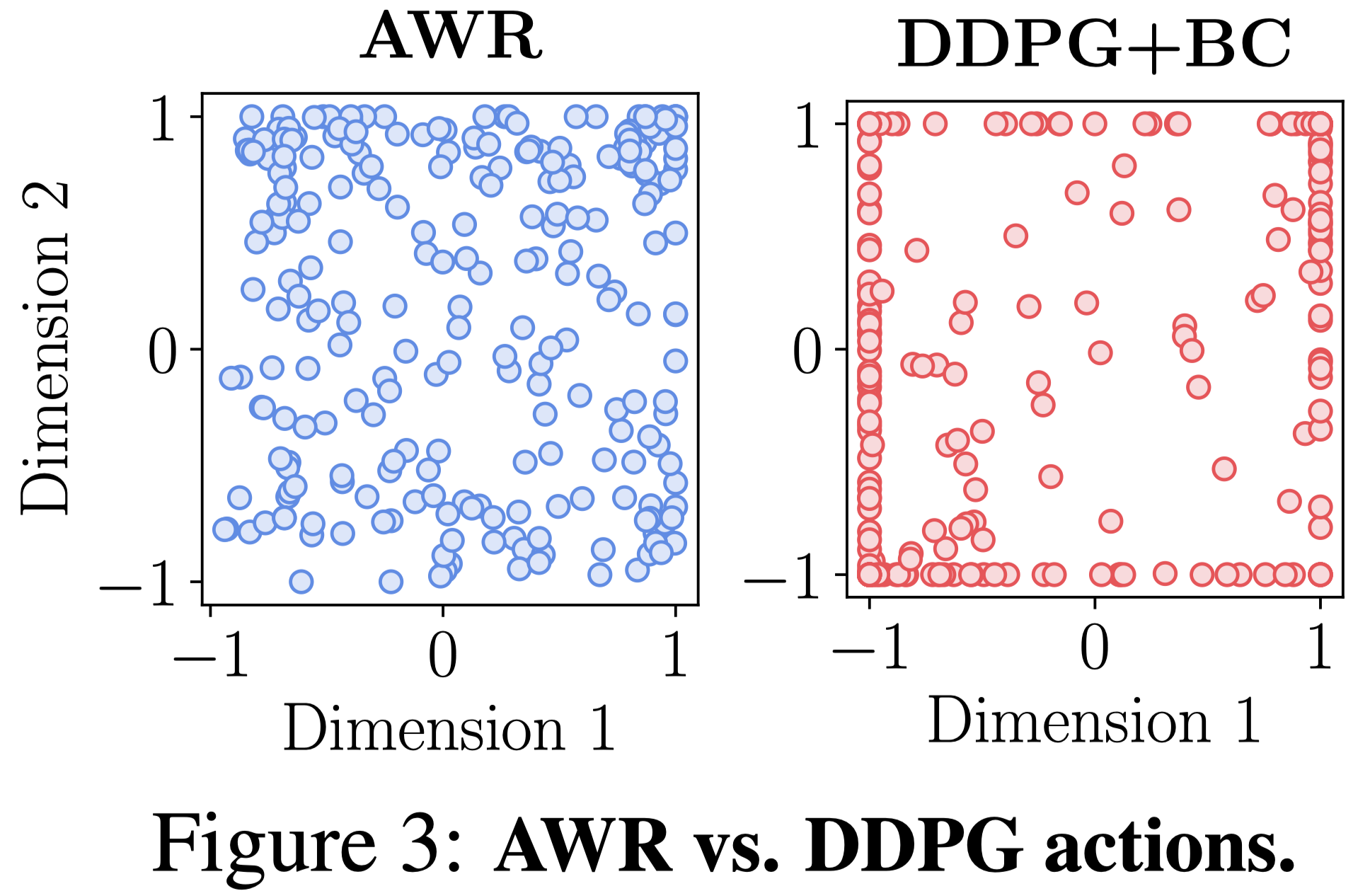
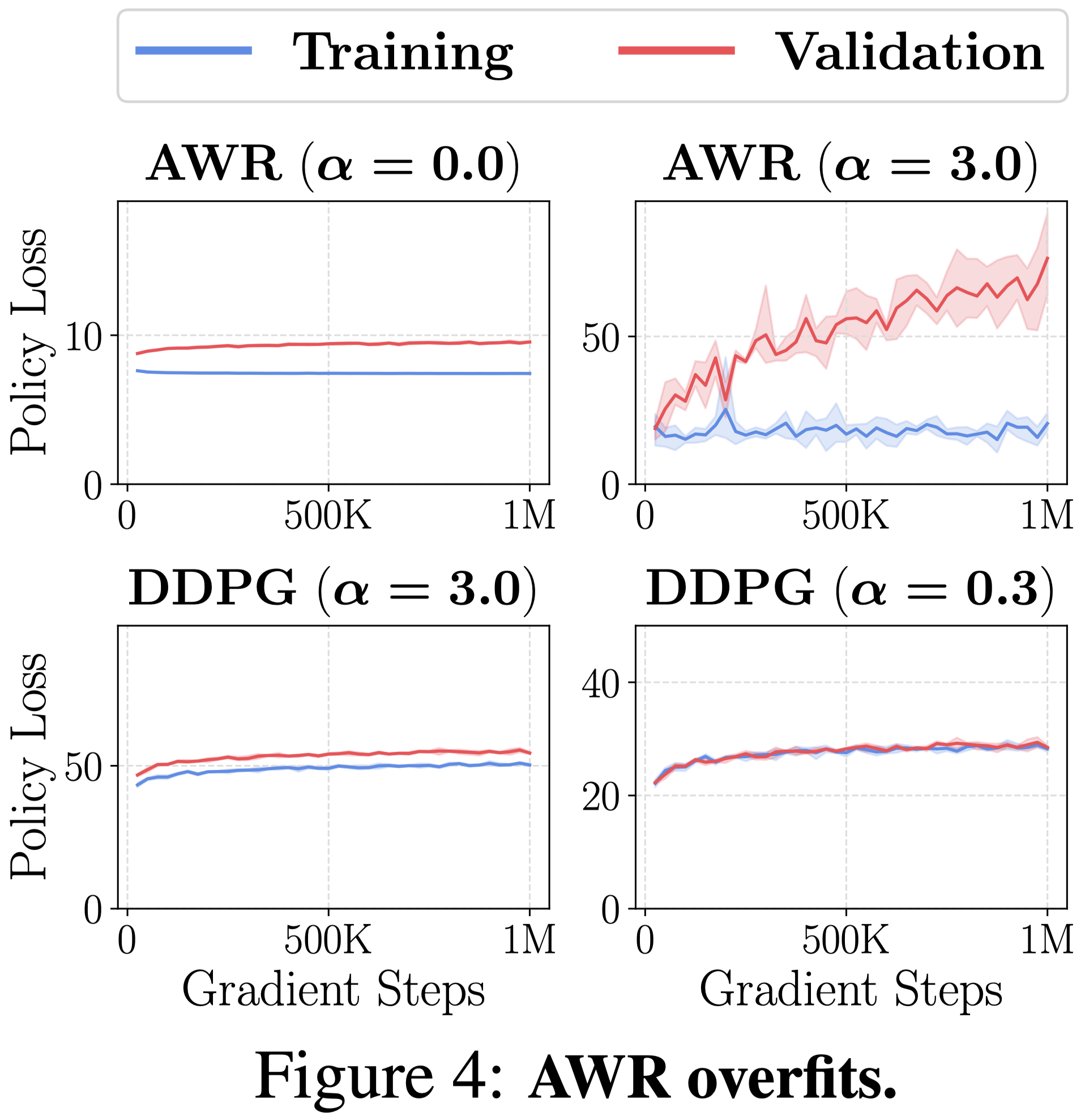
-
In the paper, we further dig into the difference between AWR and DDPG+BC from several different perspectives.
Just to make you curious, we put two figures above without descriptions. 😄
Takeaway: Do not use weighted behavior cloning (AWR); always use behavior-constrained policy gradient (DDPG+BC). This enables better scaling of performance with more data and better use of the value function.
Analysis 2: Policy generalization (B3)
- Now, we turn our focus to the third, unique bottleneck in offline RL: policy generalization.
- In offline RL, the agent encounters new, potentially out-of-distribution states at test time, and how well it generalizes to such novel states can directly affect performance.
Analysis setup
-
To understand this generalization bottleneck, we first define three key metrics quantifying policy accuracy:
$$\begin{alignat}{2} (\text{Training MSE}) &= \mathbb{E}_{s \sim \mathcal{D}_\mathrm{train}}&[(\pi(s) - \pi^*(s))^2], \\ (\text{Validation MSE}) &= \mathbb{E}_{s \sim \mathcal{D}_\mathrm{val}}&[(\pi(s) - \pi^*(s))^2], \\ (\text{Evaluation MSE}) &= \mathbb{E}_{s \sim p^\pi(\cdot)}&[(\pi(s) - \pi^*(s))^2], \end{alignat}$$ $$\begin{alignat}{2} (\text{Training MSE}) &= \mathbb{E}_{s \sim \mathcal{D}_\mathrm{train}}&[(\pi(s) - \pi^*(s))^2], \\ (\text{Validation MSE}) &= \mathbb{E}_{s \sim \mathcal{D}_\mathrm{val}}&[(\pi(s) - \pi^*(s))^2], \\ (\text{Evaluation MSE}) &= \mathbb{E}_{s \sim p^\pi(\cdot)}&[(\pi(s) - \pi^*(s))^2], \end{alignat}$$ where \(\mathcal{D}_\mathrm{train}\) and \(\mathcal{D}_\mathrm{val}\) respectively denote the training and validation datasets, \(p^\pi(\cdot)\) denotes the state-marginal distribution of the policy \(\pi\), and \(\pi^*\) denotes an optimal (expert) policy.
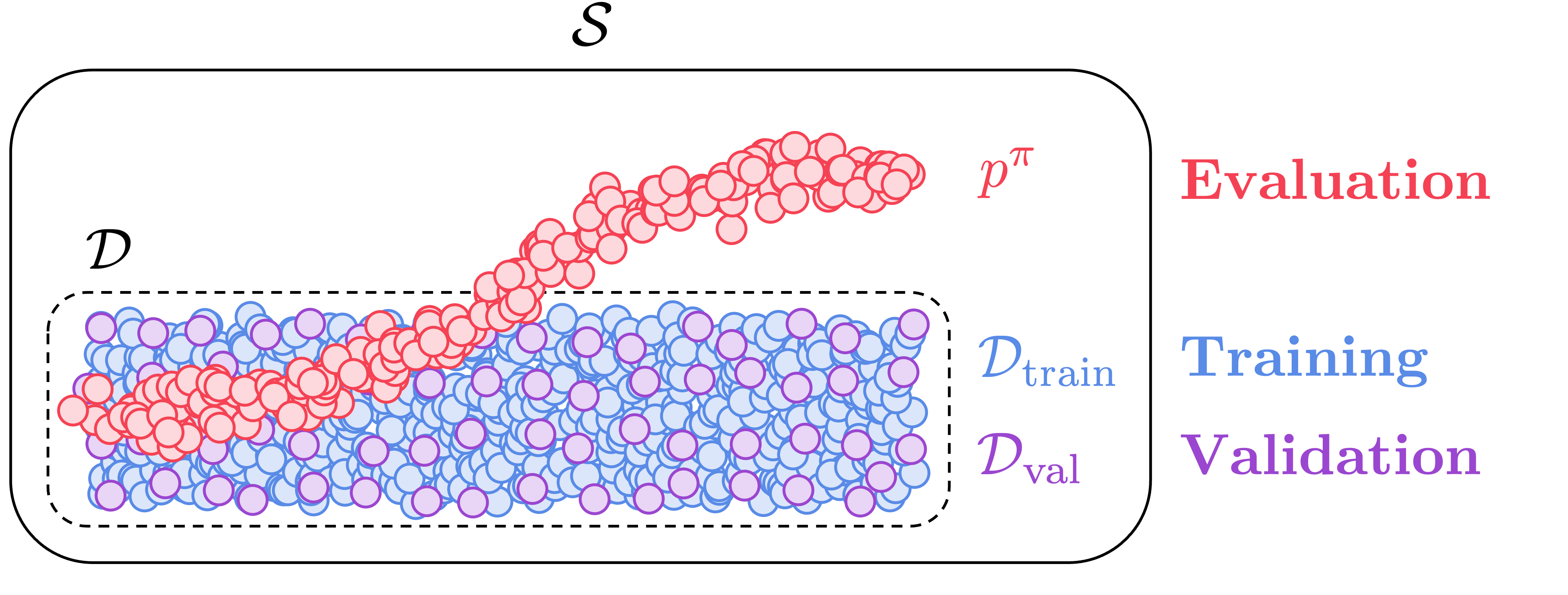
- Intuitively, these metrics measure how accurate the policy is on three different distributions.
- Perhaps you're already familiar with training MSE and validation MSE. But we have another metric: evaluation MSE, which might look similar to validation MSE but is actually very different.
- The key difference between validation MSE and evaluation MSE is that validation MSE measures in-distribution policy accuracy, but evaluation MSE measures out-of-distribution policy accuracy (see the figure above). Evaluation MSE precisely corresponds to the generalization bottleneck that we're going to measure.
- To see how these quantities correlate with performance, we observe how these metrics and performance evolve with additional online interaction data (commonly referred to as the offline-to-online RL setting).
Results
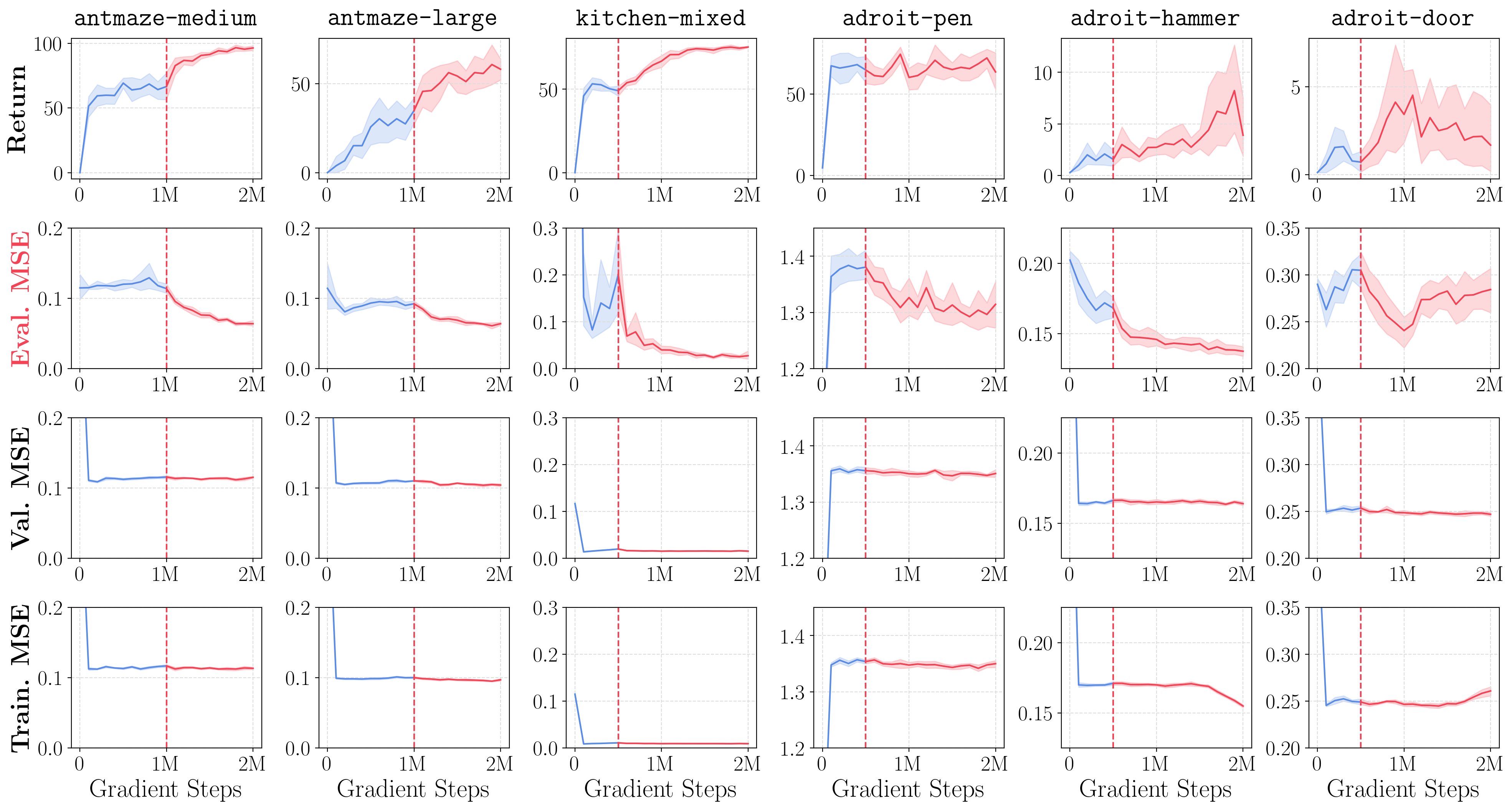
- The plots above show how returns and MSE metrics improve with additional online interaction data. We denote online training steps in red.
- The results are quite surprising! We can see that (1) offline-to-online RL mostly only improves evaluation MSEs, while validation MSEs and training MSEs often remain completely flat, and (2) the performance of offline RL is very strongly (inversely) correlated with the evaluation MSE metric.
- What does this mean? This means that current offline RL algorithms may already be sufficiently great at learning the best possible policy within the distribution of states covered by the offline dataset, and the performance is often simply determined by the policy accuracy on novel states that the agent encounters at test time!
- This provides a new perspective on generalization in offline RL, which is somewhat very different from the previous focus on pessimism and behavioral regularization.
- Then, how can we improve test-time policy generalization? Unfortunately, this is very difficult in principle, because it requires generalization to a potentially completely different distribution. Nonetheless, we can address this issue if we slightly relax assumptions, and we propose two such solutions in this work.
Solution 1: Improve offline data coverage
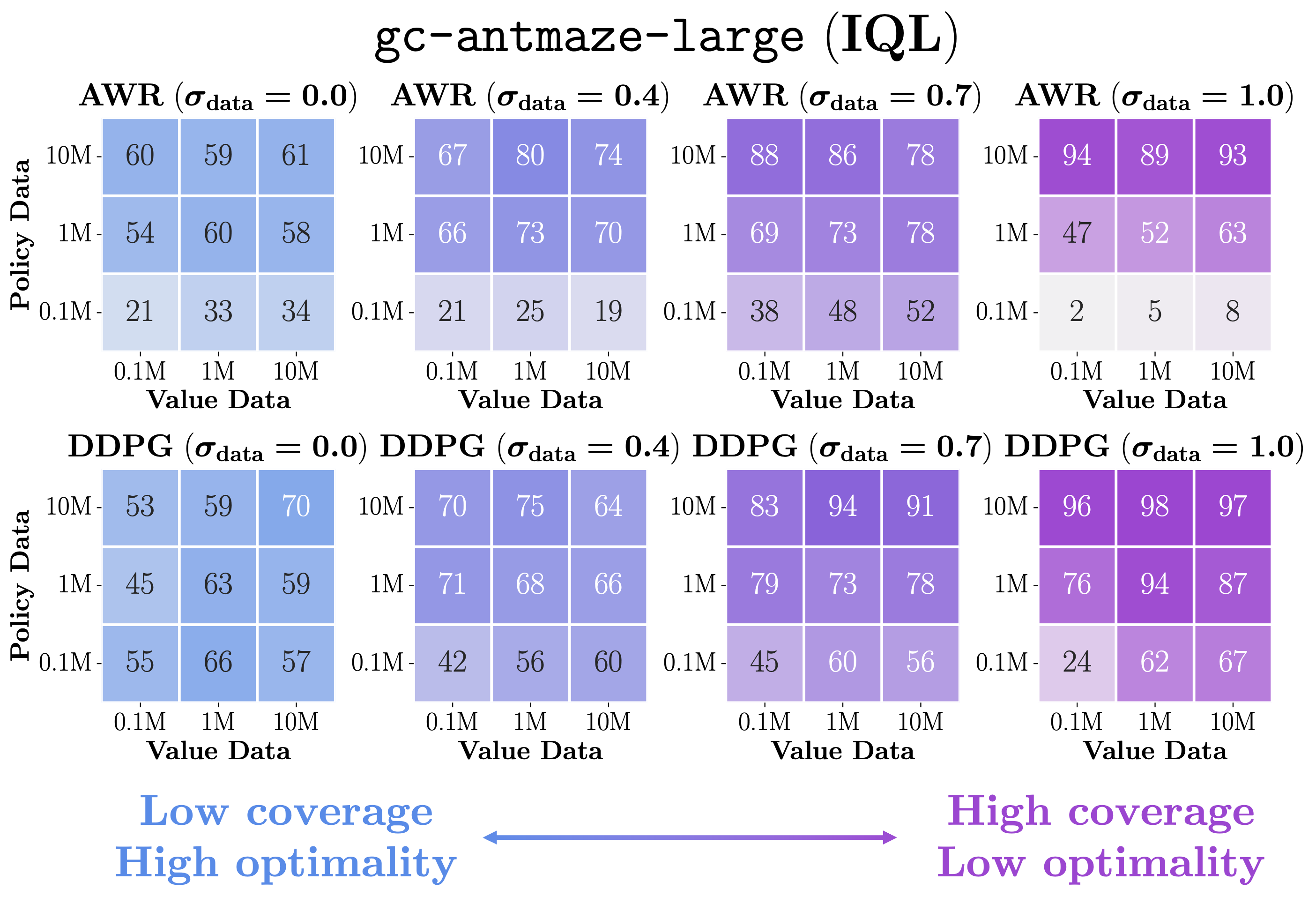
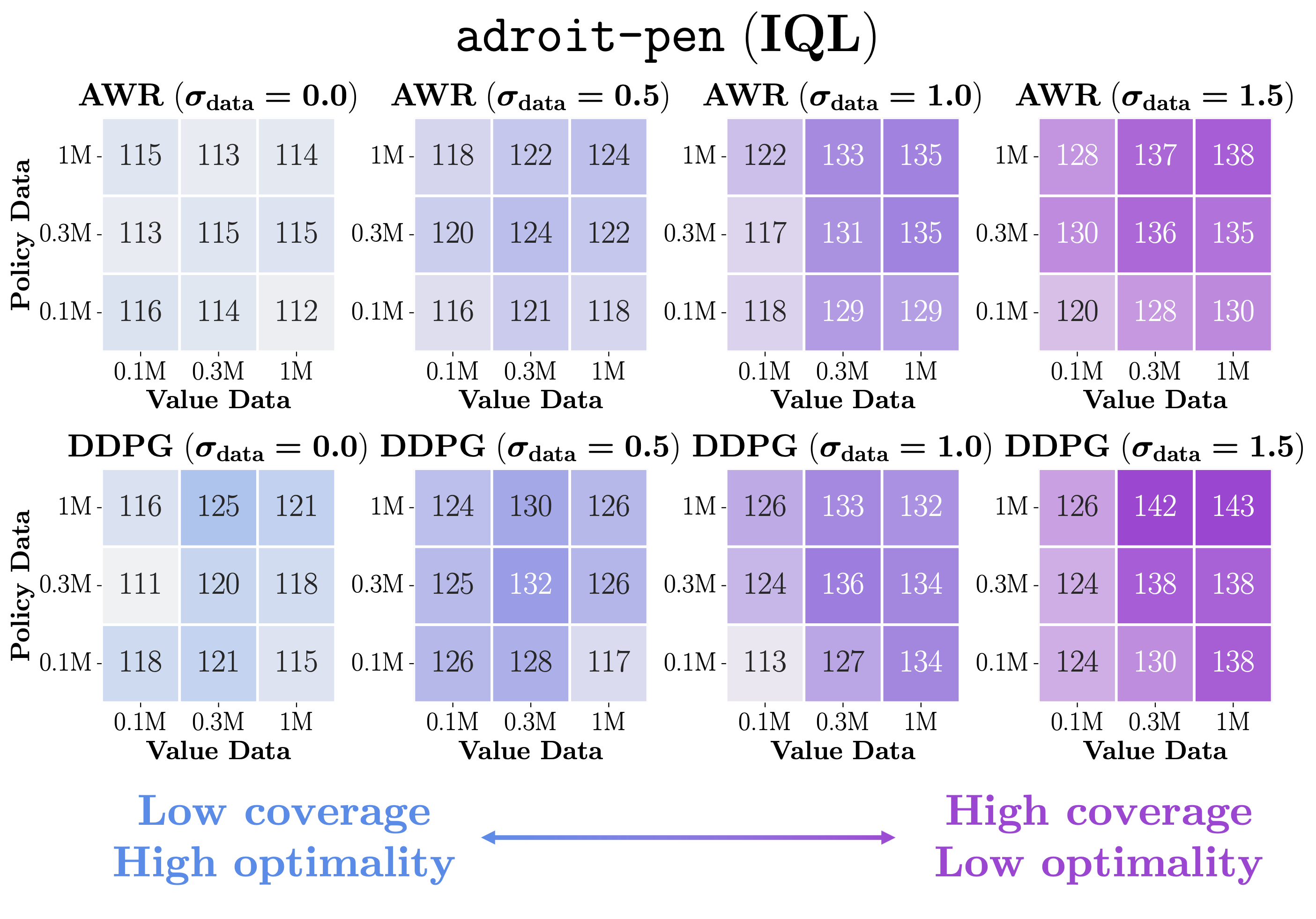
- Our first solution is to use a high-coverage dataset.
- The rationale is very simple: if test-time out-of-distribution generalization is the bottleneck, we can simply make test-time states in-distribution with more data (of course, when it's possible to collect more data 🙂)!
- In the plots above, we show that high-coverage datasets indeed improve performance, despite their increased suboptimality. Also, note that the use of a right policy extraction objective (DDPG+BC) is important in this case as well!
Solution 2: Test-time policy improvement
- If we don't have control over data, another way to improve test-time policy accuracy is to on-the-fly train or steer the policy on test-time states.
- To do this, we propose a really simple method in the paper, which we call on-the-fly policy extraction (OPEX). Our key idea is to simply adjust policy actions in the direction of the value gradient at evaluation time.
- Specifically, after sampling an action from the policy \(a \sim \pi(· | s)\) at test time, we further adjust the action based on the frozen learned Q function with the following formula. $$\begin{align} a \gets a + \beta \cdot \nabla_a Q(s, a), \end{align}$$ where \(\beta\) is a hyperparameter that corresponds to the test-time "learning rate".
- OPEX requires only a single line of additional code at evaluation and does not change the training procedure at all!
- In the paper, we propose another method named test-time training (TTT), which further updates policy parameters during test-time rollouts.
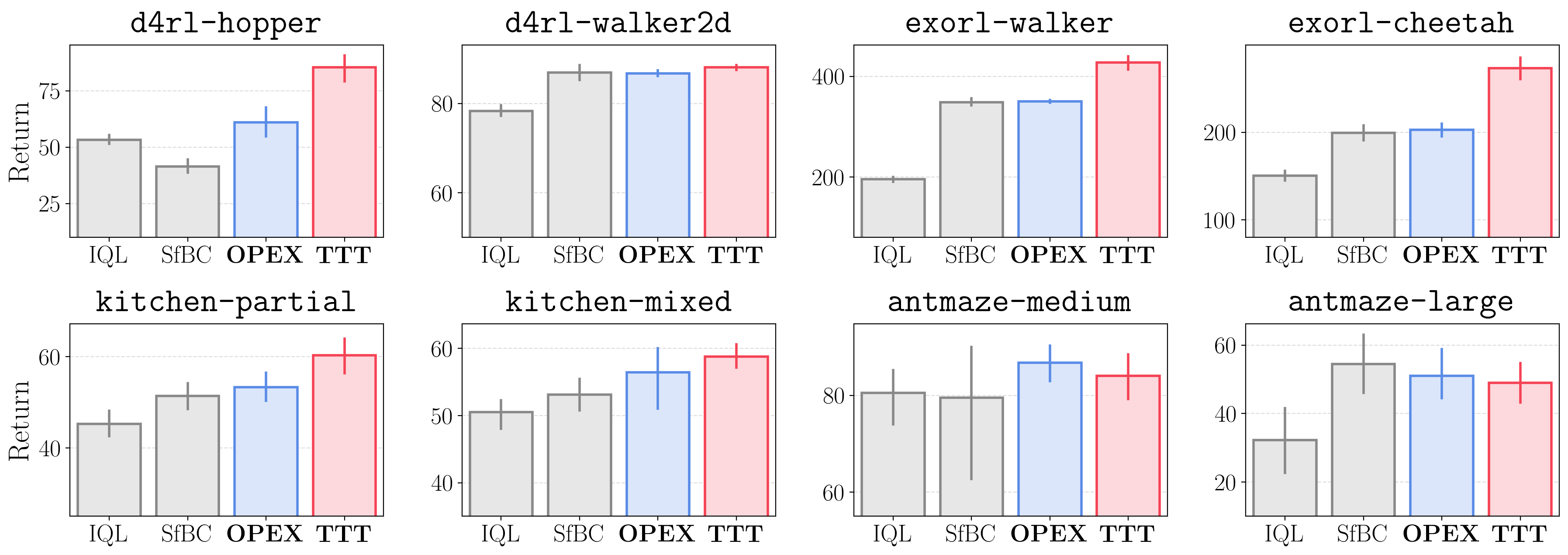
-
We show that these on-the-fly policy improvement techniques improve performance on diverse tasks, by mitigating the test-time policy generalization bottleneck.
Takeaway: Test-time policy generalization is one of the most significant bottlenecks in offline RL. Use high-coverage datasets. Improve policy accuracy on test-time states with on-the-fly policy improvement techniques.
So, what does our analysis tell us?
- We showed that, somewhat contrary to the prior belief that value learning is the main bottleneck of offline RL, current offline RL methods are often heavily bottlenecked by how faithfully the policy is extracted from the value function and how well this policy generalizes to test-time states.
- For practitioners, our analysis indicates a clear recipe for offline RL: train a value function on as diverse data as possible, and allow the policy to maximally utilize the value function, with the best policy extraction objective (e.g., DDPG+BC) and/or potential test-time policy improvement strategies.
-
For future algorithms research, we emphasize two important open questions in offline RL:
- (1) What is the best way to extract a policy from the learned value function? Is there a better way than DDPG+BC?
- (2) How can we train a policy in a way that it generalizes well on test-time states?
- The second question is particularly very interesting, because it suggests a diametrically opposed viewpoint to the prevailing theme of pessimism in offline RL, where only a few works have explicitly aimed to address this generalization aspect of offline RL!
- We hope that finding satisfying answers to these questions would lead to significant breakthroughs in offline RL, and encourage the community to incorporate a holistic picture of offline RL along the current mainstream research on value function learning.
The website template was borrowed from Michaël Gharbi and Jon Barron.