Controllability-Aware Unsupervised Skill Discovery
ICML 2023
-
Seohong Park
UC Berkeley -
Kimin Lee
Google Research -
Youngwoon Lee
UC Berkeley -
Pieter Abbeel
UC Berkeley
Abstract
One of the key capabilities of intelligent agents is the ability to discover useful skills without external supervision. However, the current unsupervised skill discovery methods are often limited to acquiring simple, easy-to-learn skills due to the lack of incentives to discover more complex, challenging behaviors. We introduce a novel unsupervised skill discovery method, Controllability-aware Skill Discovery (CSD), which actively seeks complex, hard-to-control skills without supervision. The key component of CSD is a controllability-aware distance function, which assigns larger values to state transitions that are harder to achieve with the current skills. Combined with distance-maximizing skill discovery, CSD progressively learns more challenging skills over the course of training as our jointly trained distance function reduces rewards for easy-to-achieve skills. Our experimental results in six robotic manipulation and locomotion environments demonstrate that CSD can discover diverse complex skills including object manipulation and locomotion skills with no supervision, significantly outperforming prior unsupervised skill discovery methods. Videos and code are available at https://seohong.me/projects/csd/.
Motivation
Humans are capable of autonomously learning skills, ranging from basic muscle control to complex acrobatic behaviors, which can be later combined to achieve highly complex tasks. Can machines similarly discover useful skills without any external supervision?
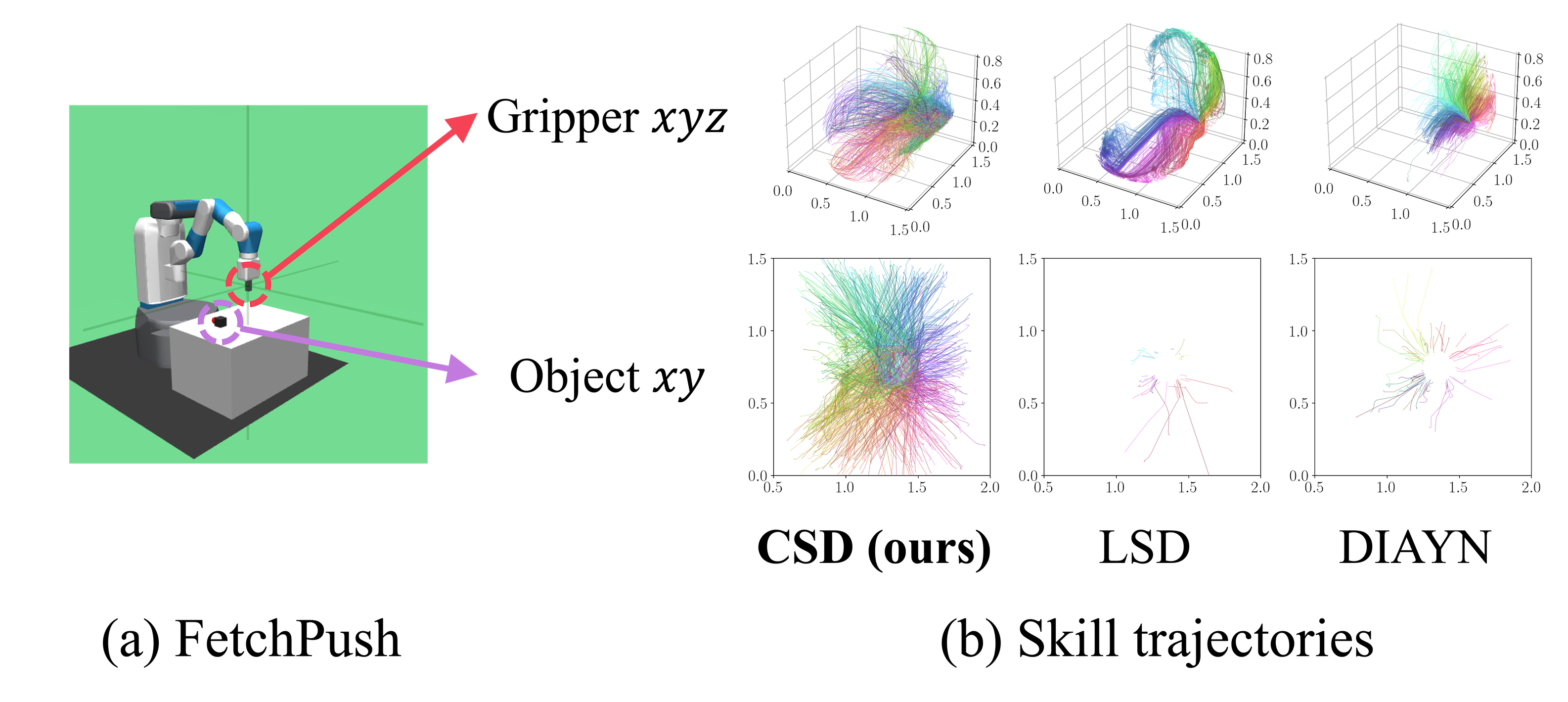
Many unsupervised skill discovery methods have recently been proposed to discover diverse behaviors in the absence of extrinsic rewards. However, in complex environments, they are often limited to discovering only simple, easy-to-learn skills. For example, in the Fetch environment above, previous approaches (LSD and DIAYN) only learn to gain control of the agent's own 'body' (i.e., the gripper and joint angles), completely ignoring the object. This is because there is little incentive for them to discover complex and thus potentially more useful skills.
Method Overview

We briefly explain why previous skill discovery methods often tend to discover simple skills.
- First, the widely used mutual information objective \(I(S; Z)\) is invariant to traveled distances. Since there is no incentive for the MI objective to further explore the state space, they often end up discovering 'static' skills with limited state coverage.
- LSD, one of the state-of-the-art skill discovery methods, does maximize traveled distances. However, it only considers the Euclidean distance metric, which does not necessarily match the behaviors of our interests.
To resolve these limitations, we propose to maximize traveled distances with respect to a learned controllability-aware distance function. This distance function 'stretches' the axes along hard-to-control states (e.g., objects) and 'contracts' the axes along easy-to-control states (e.g., joint angles), so that maximizing traveled distances results in the discovery of more complex, useful behaviors. We therefore call our method Controllability-aware Skill Discovery (CSD). We refer to our paper for further details about the controllabaility-aware distance function and its practical implementation.
Kitchen Results
CSD (ours)
(16 discrete skills)
CSD (ours)
(2-D continuous skills)
LSD
(2-D continuous skills)
DIAYN
(2-D continuous skills)
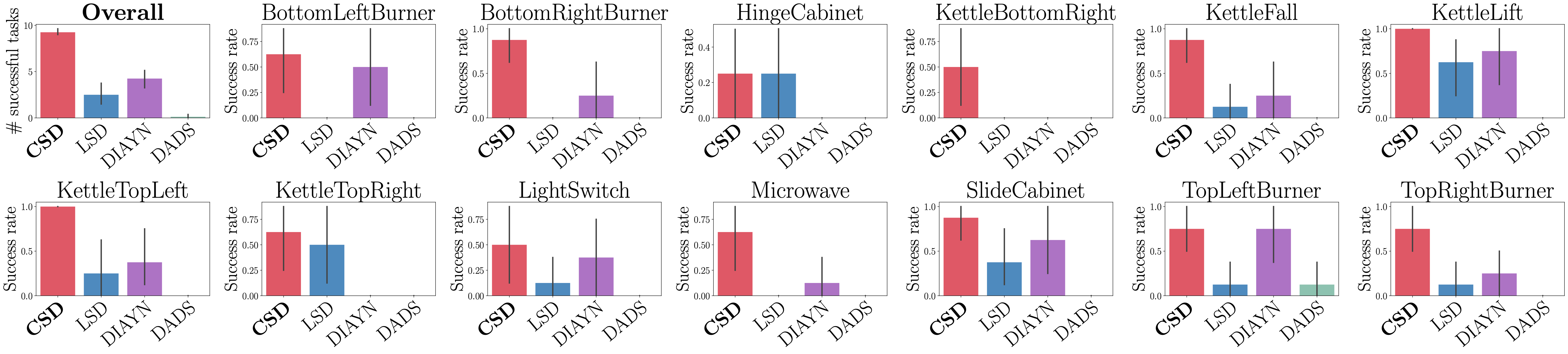
In the Kitchen environment, CSD learns to manipulate diverse kitchen objects in the absence of any supervision or external supervision. On the other hand, previous methods mostly focus on diversifying the pose of the robot arm because there is no incentive for them to discover more complex, challgenging skills.
Fetch Results
CSD (ours)
(2-D continuous skills)
LSD
(2-D continuous skills)
DIAYN
(2-D continuous skills)
In Fetch environments, CSD learns to interact with the object without any supervision, while previous approaches only focus on the internal states of the robot.
Ant and HalfCheetah Results
CSD (ours)
(16 discrete skills)
Disagreement-based exploration
DIAYN
(16 discrete skills)
CSD (ours)
(16 discrete skills)
Disagreement-based exploration
DIAYN
(16 discrete skills)
CSD discovers consistent, directed behaviors in MuJoCo locomotion environments. In contrast, unsupervised exploration solely focuses on diversifying the state with chaotic, random behaviors, and the mutual information objective only discovers static skills.
The website template was borrowed from Michaël Gharbi and Jon Barron.